How to run LLMs locally using Ollama
3 minutes read
PS: This post has definitely not been written using Ollama.
What’s Ollama?
Ollama provides an easy way to manage LLMs. It’s a command-line app that lets you run large language models right on your computer. It’s built on top of llama.cpp, a C++ library that makes it easy to run models on CPUs or GPUs.
Whether you’re using an older GPU or don’t have one at all, Ollama’s got you covered. It’s designed to be simple and focused, making it a breeze to get started with LLMs.
How do I run models locally?
Simple. Just run this in the terminal if you’re on GNU+Linux or macOS.
|
If you’re on Windows, download the executable from the website and run the setup file. This will setup an Ollama service (on all of the above operating systems).
To pull your first model,
I’ve used Neural-chat for example purposes, but other models such as LLaMa2 are also available. Some models, such as LLaVA, even have visual understanding capabilities such as identifying details in images.
Ugh, this is a pain to use. Is there a better way?
Of course! Running LLMs this way in a terminal is boring! One can use Open WebUI for this. I’ll be running it via Podman; Docker can also be used to achieve this.
If you are using Docker instead of Podman:
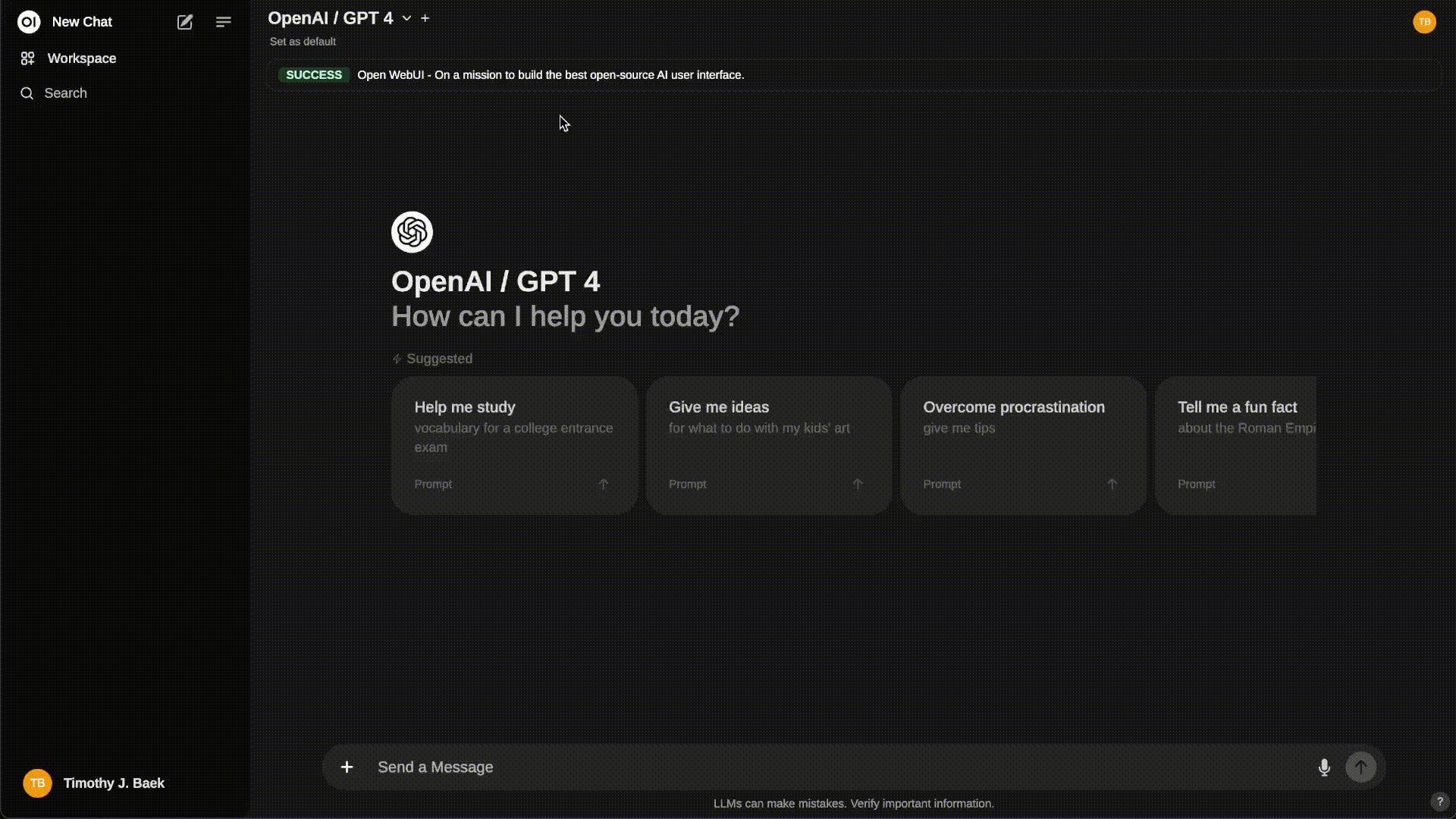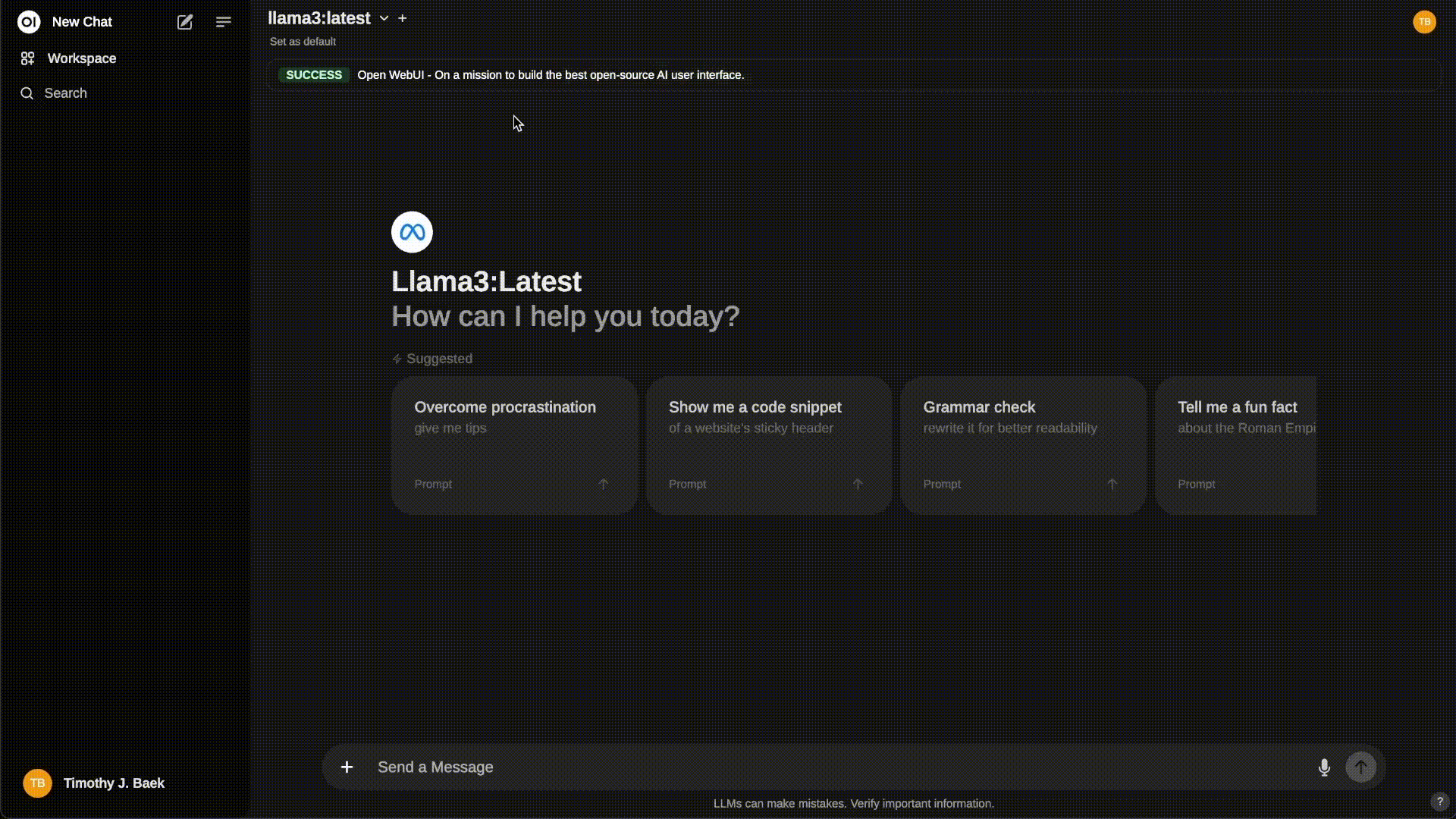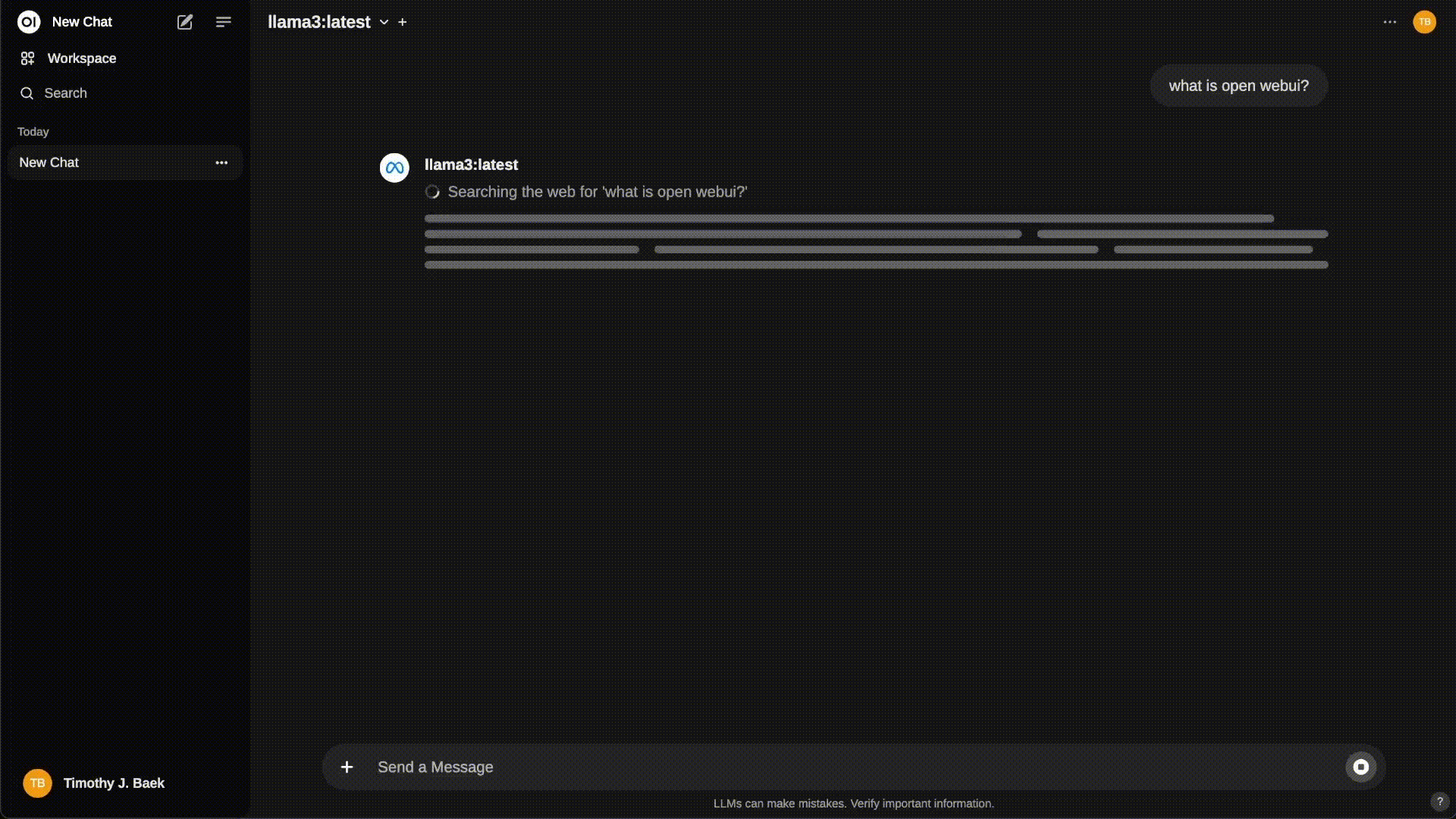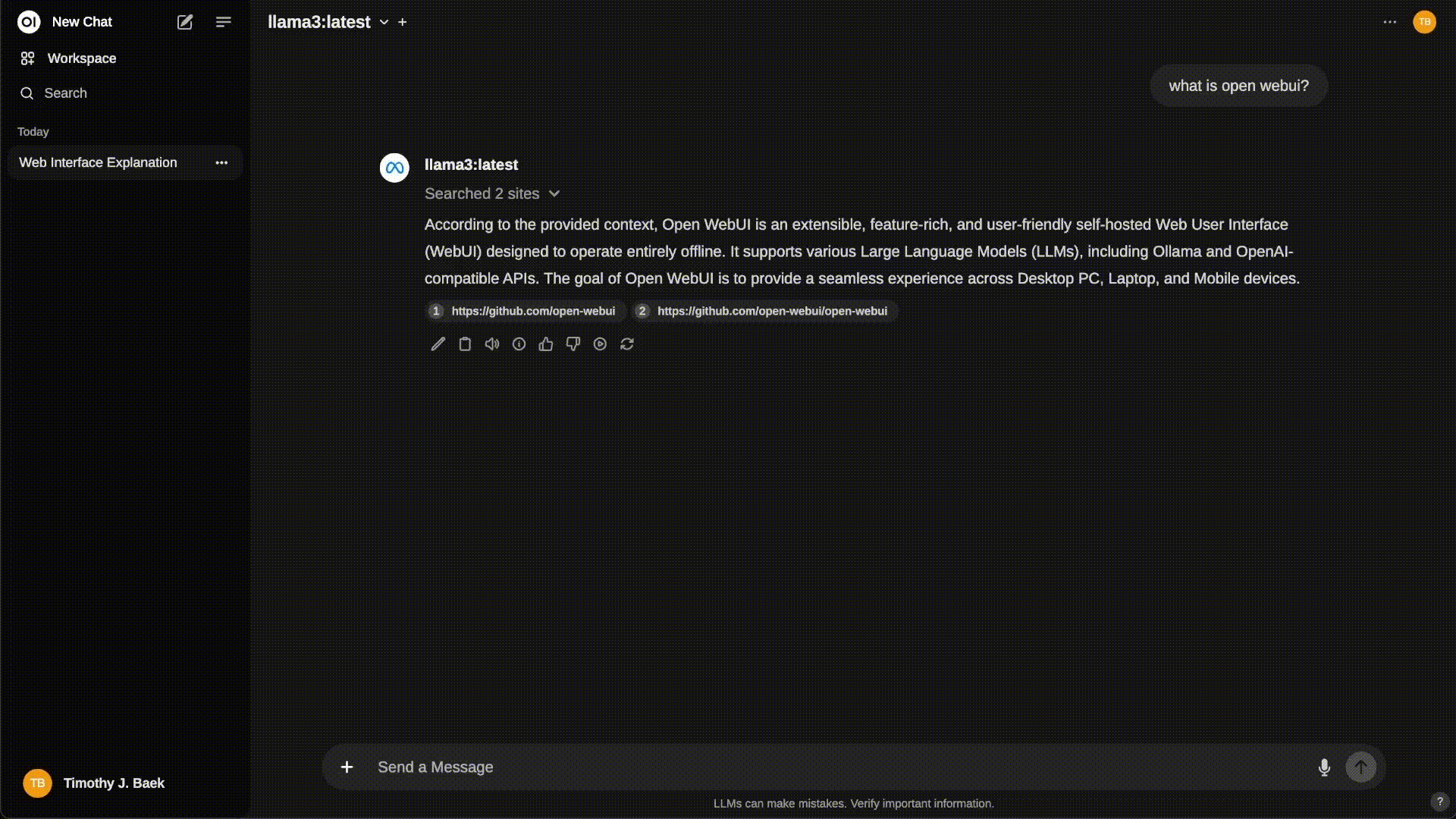
Now open a browser and start configuring Open-WebUI! Here’s a demo on how to use Open-WebUI.
{kind=link}
Bonus
Here’s how you can configure Emacs to use Ollama using GPTel. I’m using straight and hence this can be pulled from the GitHub repo. If you’re not using Straight.el, instructions may vary:
I’ve configured GPTel (and hence Ollama) to use neural-chat because I’ve pulled the model locally. Feel free to choose any other model(s) of your liking.
Fin
Pick and choose the model of your choice. The more parameters a model has been trained on (e.g 3B,7B,13B) etc, the more resource-intensive it will be. On my potato laptop (which lacks have a dGPU) running these models places a strain on my CPU and can consume a ton of memory. But I guess that’s fine. These models don’t send telemetry data anywhere. Thanks for reading!